How AI Works: From Neural Networks to Real-World Use
Educational | 23-04-2025 | By Robin Mitchell
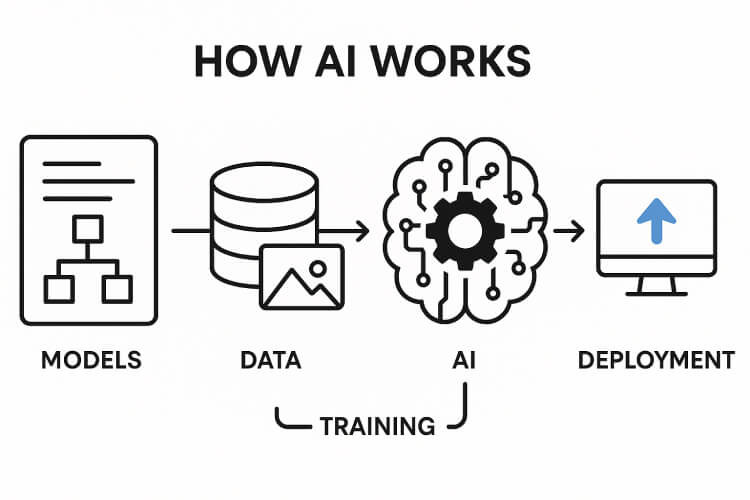
Image generated using AI – DALL·E.
Table of Contents:
- Introduction: What Powers Artificial Intelligence?
- Understanding AI Models: Size Matters (But Not Always How You Think)
- Small AI Models: Lightweight, Fast, and Efficient
- Large AI Models: Powering Creativity and Complex Tasks
- Inside the Neural Network: How Weighted Neurons Learn
- The AI Development Pipeline: From Data to Deployment
- Real-World Applications: Where AI Has Been Integrated
- The Importance of Ethical AI
- Conclusion: The Expanding Role of AI in Our World
- Multimodal AI: The Next Frontier
- Glossary of Key AI Terms
- Frequently Asked Questions: How AI Works
Introduction: What Powers Artificial Intelligence?
At its core, artificial intelligence (AI) works by replicating key aspects of human cognition, such as learning from experience, recognising patterns, making decisions, and adapting over time. Much like the human brain processes sensory input to generate a response, AI systems rely on data and algorithms to understand their environment and take action. Understanding how AI works means recognising that these systems don't just follow static rules—they evolve, improve, and adapt based on the information they process.
How AI works in simple terms: AI mimics how humans think by analysing data, learning from patterns, and making decisions automatically. It does this through computer programs called models that are trained using large datasets.
This process is made possible through models—structured systems that represent knowledge and decision-making logic. These models, whether simple or highly complex, are trained on vast amounts of data to uncover relationships and patterns that would be difficult or impossible to program manually. Much like how a person learns from repeated exposure and feedback, AI models improve through experience, adjusting their internal parameters to refine performance over time.
From recognising faces in photos to generating human-like responses in chat, the power of AI lies in its ability to process information in a way that mimics the adaptive nature of the human mind. The key difference? AI learns through data, not consciousness.
To understand how today's AI systems came to be, it's worth exploring the key breakthroughs that shaped their development. Discover the history of AI and its transformative milestones.
Understanding AI Models: Size Matters (But Not Always How You Think)
At the heart of any AI system is the model, and this model can range from tiny to ungodly massive. Undoubtedly, the size of a model will influence its capabilities, but just because an AI model has a reduced scale or narrower focus doesn't mean that it is any less practical. In fact, in many cases, the opposite is often true—smaller models are not only viable but frequently preferred for specific tasks.
The size of an AI model generally reflects the number of parameters it contains—essentially, the "knobs" it can adjust to learn from data. Larger models with billions of parameters can handle highly complex and nuanced tasks, but they come at a cost: increased computational demand, energy consumption, and hardware requirements. Meanwhile, compact models can run efficiently on edge devices or low-power hardware, making them better suited for real-time applications, especially where bandwidth, storage, or energy is limited.
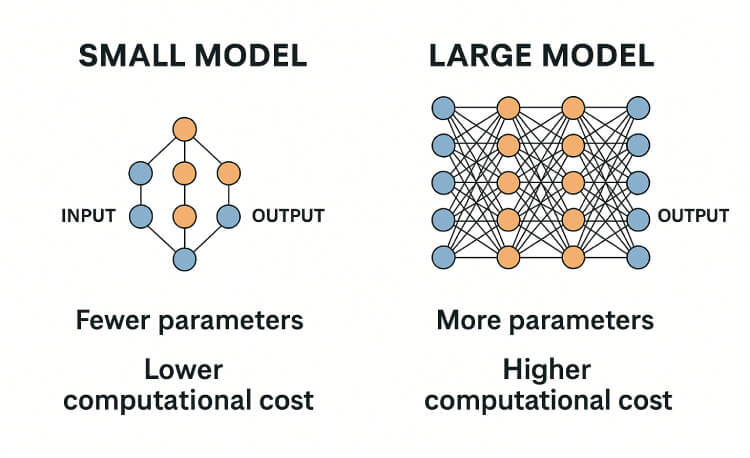
Visual comparison of small vs. large AI models – highlighting differences in size, complexity, hardware requirements, and typical use cases.
Small AI Models: Lightweight, Fast, and Efficient
Small AI models are typically utilised for narrow, targeted tasks such as predictive maintenance, fault detection, or other similar applications. These models are characterised by their efficiency and lightness, often running on edge computing devices such as Internet of Things (IoT) sensors, mobile apps, or other resource-constrained platforms. Examples of small AI models include simple regression models, small neural networks, and decision trees, which are designed to handle straightforward classification and prediction tasks.
The advantages of small AI models lie in their ability to operate effectively in resource-constrained environments. For instance, predictive maintenance models can be deployed on industrial sensors to monitor equipment in real time, identifying potential faults before they escalate into costly failures. Similarly, small neural networks can be integrated into mobile apps to enhance user experiences by providing intelligent recommendations or predictive features. Because they require minimal compute and memory, the efficiency of small AI models enables them to operate on edge devices, eliminating the need for remote data processing and thereby reducing latency and improving overall performance. This also enhances privacy, as sensitive data can often remain on the device rather than being transmitted to external servers.
Large AI Models: Powering Creativity and Complex Tasks
In contrast to small AI models, large AI models are designed to tackle complex tasks that require substantial computational resources and large datasets. These models are commonly found in systems such as Large Language Models (LLMs), which are capable of generating text, analysing patterns, and producing creative content. Examples of large AI models include GPT-type models and BERT, which are transformer-based architectures known for their advanced language processing capabilities.
Transformer models, introduced in 2017, form the backbone of most state-of-the-art language systems today. They rely on mechanisms such as self-attention to understand context across entire sequences, enabling far more nuanced understanding and generation of language than previous model types.
The training process for large AI models is often a computationally intensive task that requires significant resources. These models are typically trained on massive datasets, which can include millions or even billions of examples and are often trained for extended periods of time. The resulting models can be hundreds of times larger than their smaller counterparts, with billions of parameters and complex neural network architectures.
While these models are computationally expensive to train, they offer unparalleled capabilities in tasks such as language generation, natural language processing, and content creation. Their generalisation abilities allow them to adapt across a wide range of use cases—from generating human-like dialogue to translating languages or even writing functional code.
Inside the Neural Network: How Weighted Neurons Learn
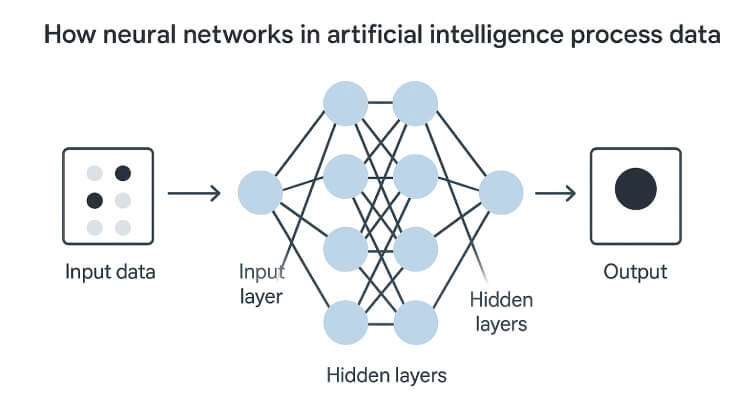
At its core, AI mimics aspects of the human brain through neural networks, which are a fundamental concept in the field of artificial intelligence. These networks consist of layers of nodes, commonly referred to as neurons, that are connected by weighted links. Each neuron plays a critical role in the operation of the network, and the weights assigned to the connections between them determine the network's output.
How neural networks in artificial intelligence process data through weighted connections, activation functions, and layered structures.
The Forward Pass: Turning Input into Output
The forward pass of a neural network involves inputting data—such as an image or text—into the system. As this data flows through the network, each neuron applies a mathematical function, often referred to as an activation function, to the input signals it receives. The output of each neuron is then passed to the next layer, creating a cascading effect as the data moves through the network. The weights assigned to each connection determine the significance of the input signals, with higher weights indicating a stronger impact on the neuron's output. This mechanism enables the model to emphasise certain patterns over others—such as edges in an image or key phrases in a sentence—thereby shaping its overall prediction.
Backpropagation: Learning from Mistakes
The training process of a neural network involves a series of steps to teach the model to make accurate predictions. Initially, the weights assigned to each connection are random, and the network makes predictions based on this initial setup. After the forward pass generates an output, the error between the prediction and the actual label is calculated. This error is then propagated back through the network in a process known as backpropagation. The backpropagation algorithm computes how much each weight contributed to the error, allowing the system to adjust its internal structure accordingly. During this process, the weights of the connections are adjusted to minimise future errors. This iterative training continues until the network converges on an acceptable level of accuracy.
The degree to which each weight is adjusted is determined by a learning rate—a parameter that controls how quickly or slowly the model updates itself during training. Striking the right balance in this learning rate is crucial; if it's too high, the model may overshoot optimal settings, and if it's too low, training may become excessively slow or stagnate.
Why Weighted Neurons Matter
The concept of weighted neurons and iterative training enables AI systems to learn patterns and relationships within data. By updating the weights based on errors, neural networks can be trained to recognise faces, predict outcomes, and even generate human-like responses to text-based inputs. This approach also allows models to generalise and perform well not just on training data but also on new, unseen examples.
The effectiveness of this approach has led to the development of various neural network architectures, including convolutional neural networks (commonly used in image recognition) and transformer models (widely used in natural language processing). Each of these architectures is tailored to different data types and challenges, yet they all rely on the same foundational principle: learning through weighted connections.
The AI Development Pipeline: From Data to Deployment
Training AI models is just one of the many challenges faced during the development of artificial intelligence; suitable data for training needs to be found, models need to be trained efficiently, and hardware capable of running those models needs to be developed. To fully understand how an AI system comes to life, it's important to explore each stage in the pipeline—from data collection to real-world deployment. So, what exactly are the steps (and in what order) when developing a new AI model?
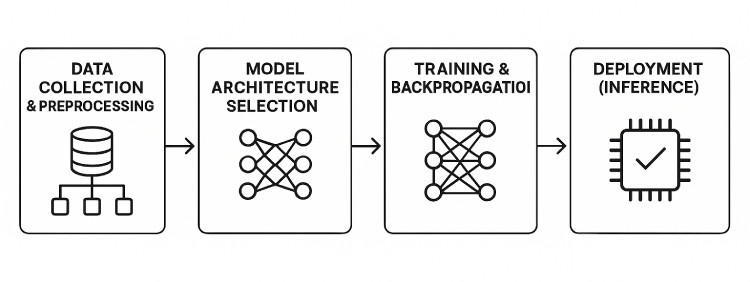
Diagrammatic overview of the AI development pipeline – from data collection and model architecture selection to training, validation, and real-world deployment. Image generated using AI – DALL·E.
Data Collection & Preprocessing
The foundation of any AI model lies in the quality and quantity of the data used for training. Gathering large, high-quality datasets is a critical step in the AI pipeline, as it directly impacts the performance and reliability of the final model. However, collecting data can be a time-consuming and resource-intensive process, especially when dealing with complex tasks or specialised domains.
Once the data is collected, it must undergo preprocessing to prepare it for training. This step involves cleaning, formatting, and labelling the data to remove any inconsistencies or biases that may affect the model's performance. Data augmentation techniques may also be applied to artificially expand the dataset and improve generalisation. The quality of the data at this stage has a direct impact on the accuracy of the final model, making data preprocessing a critical component of the AI pipeline.
Model Architecture Selection
With high-quality data in hand, the next step is to select the appropriate model architecture for the task at hand. Choosing between simpler models and more complex deep networks depends on the task's complexity and the size of the dataset. For example, a predictive maintenance model may require a simpler model that can operate on edge devices, while a large language model may necessitate a more complex architecture that can handle vast amounts of data.
The selection of the model architecture also plays a crucial role in determining the computational resources required for training and deployment. Larger models often require more powerful hardware and longer training times, which can be a significant challenge in resource-constrained environments. At this stage, frameworks such as TensorFlow, PyTorch, or ONNX may be selected based on the model type and deployment target.
Training & Backpropagation
With the model architecture in place, the next step is the training process itself. This involves feeding the data through the network, calculating losses, and adjusting the weights via backpropagation. The goal of this process is to minimise the error between the model's predictions and the true labels, ensuring that the model learns to recognise patterns and relationships in the data.
The training process can be computationally intensive, requiring significant resources and time. However, advances in hardware and software have made it possible to train large models on a single GPU or even a mobile device. Additionally, distributed training techniques allow for training models across multiple devices, significantly reducing the training time and improving the model's performance.
Techniques like batch normalisation, dropout, and learning rate scheduling are often employed during training to stabilise learning and avoid overfitting.
Validation & Testing
Once the model has been trained, it is essential to validate and test its performance on unseen data. This step ensures that the model generalises well and does not simply memorise the training examples. The validation process typically involves splitting the data into training and testing sets, with the model being trained on the former and evaluated on the latter.
The performance of the model on the testing set is a critical metric for evaluating its quality. If the model performs well on the testing set, it is likely to generalise well to new, unseen data, making it suitable for real-world deployment. However, if the model performs poorly on the testing set, further adjustments to the model architecture or training process may be necessary.
Common evaluation metrics at this stage include accuracy, precision, recall, and F1-score, depending on the problem type.
Deployment (Inference)
Once the model has been validated and tested, it is ready for deployment in real-world scenarios. The deployment of AI models typically involves using the trained model to make predictions or take actions in a specific context. For example, a chatbot may use a trained language model to generate responses to user queries, while a predictive maintenance system may utilise a trained model to predict equipment failures.
Deployment, often referred to as inference, can take place on cloud servers, edge devices, or embedded systems, depending on the use case. Optimisation of model size and resource usage is critical for ensuring efficient deployment. Larger models may require more powerful hardware and consume more resources, making them less suitable for resource-constrained environments. In contrast, smaller models may be more efficient but may compromise on performance, requiring a trade-off between model size and accuracy.
Real-World Applications: Where AI Has Been Integrated
The integration of AI into everyday applications has helped to accelerate the development of artificial intelligence, including AI models and inference hardware—creating a positive feedback loop that makes deployment increasingly seamless. The use of AI has rapidly expanded into various sectors, transforming how tasks are performed and improving efficiency in numerous industries.

Real-world AI applications across industries: smart driving systems, predictive maintenance, insurance analytics, and large language models like ChatGPT.
Smart Driving Systems
The integration of AI into autonomous vehicles has been a major advancement in the automotive industry. By leveraging AI, vehicles can now make real-time decisions regarding navigation, obstacle detection, and traffic management. This technology has the potential to significantly reduce accidents and enhance road safety.
While progress in autonomous systems has been substantial, fully replacing human drivers remains a long-term challenge—particularly in unpredictable or mixed-traffic environments.
Predictive Maintenance
In the industrial sector, AI plays a crucial role in predictive maintenance. By monitoring equipment in real-time, AI systems can identify potential faults and predict when maintenance is required. This approach not only reduces downtime and associated costs but also helps to extend the lifespan of equipment. The use of AI in predictive maintenance is particularly beneficial in environments where equipment failure can have severe consequences, such as manufacturing lines, power grids, or the aerospace industry.
Edge-deployed models often handle these tasks locally, enabling faster response times and improving reliability.
Insurance and Analytics
The insurance industry has also seen significant benefits from the integration of AI. By leveraging analytical models, AI can assess risks, detect potential fraud, and personalise insurance policies for individual customers. This not only improves the accuracy of risk assessments but also enhances the overall customer experience by providing tailored solutions. AI also enables insurers to automate claim processing and pricing, helping reduce administrative overhead and decision-making delays.
The use of AI analytics in the insurance sector has the potential to revolutionise how policies are issued, priced, and managed.
Large Language Models in Everyday Use
The introduction of large language models (LLMs), such as ChatGPT, has transformed how people interact with technology. LLMs allow users to generate human-like text, which has far-reaching implications for information search, idea generation, and problem-solving. The ability to generate content based on a prompt enables users to access vast amounts of knowledge and create content with ease.
LLMs are increasingly embedded in productivity tools, customer service platforms, and educational resources—streamlining tasks from writing and summarisation to coding assistance and conversational AI. However, their use also raises concerns about data privacy, intellectual property, and the potential for generating biased or misleading information, underscoring the need for responsible AI design and governance.
To better understand how AI is impacting industries, here are some high-profile real-world examples of AI applications in action:
- Tesla Autopilot (Smart Driving Systems): Tesla uses a combination of neural networks and sensor fusion to power its driver-assistance system. AI interprets real-time camera, radar, and ultrasonic data to navigate roads and react to dynamic environments.
- Google Translate (Transformer Architecture): Originally based on RNNs and now driven by transformer models, Google Translate demonstrates how AI can learn linguistic patterns across languages to deliver more fluent and contextually accurate translations.
- Meta's FAIR Vision Models (Image & Video AI): Meta's open-source research from the FAIR team includes self-supervised learning and computer vision systems used for content moderation, scene understanding, and AR experiences.=
- PathAI & Zebra Medical (AI in Healthcare): AI models in healthcare are revolutionising diagnostics. PathAI assists pathologists in identifying diseases from biopsy slides, while Zebra Medical uses deep learning to detect conditions like breast cancer, osteoporosis, and cardiovascular risks from medical imaging.
The Importance of Ethical AI
As artificial intelligence becomes more deeply woven into the fabric of daily life—from healthcare diagnostics and hiring algorithms to surveillance systems and generative models—the imperative for ethical AI development grows exponentially. While AI offers transformative potential, it also introduces complex societal risks that demand proactive governance.
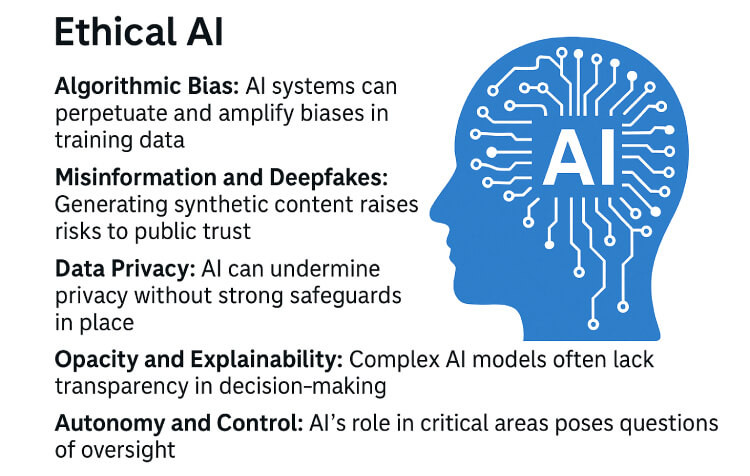
Infographic highlighting key ethical challenges in artificial intelligence, including bias, misinformation, privacy risks, and transparency issues.
Key Ethical Challenges in AI
Several pressing concerns underscore the need for ethical AI:
-
Algorithmic Bias: AI systems can perpetuate and even amplify biases present in the data they’re trained on. This has led to real-world consequences—from racial bias in facial recognition technologies to gender bias in recruitment tools.
-
Misinformation and Deepfakes: Generative models can create highly realistic synthetic content, blurring the lines between truth and fiction. This poses major risks in politics, journalism, and public trust.
-
Data Privacy: AI often relies on vast datasets, many of which contain personal or sensitive information. Without strong safeguards, AI can erode individual privacy and enable mass surveillance.
-
Opacity and Explainability: Many AI systems, particularly deep learning models, operate as "black boxes," making it difficult to understand how decisions are made. This lack of transparency complicates accountability.
-
Autonomy and Control: As AI systems take on more decision-making authority—from autonomous weapons to financial trading—there are growing questions about control, consent, and oversight.
Ethical AI in Practice: What’s Being Done?
To address these challenges, researchers, developers, and regulators are working to build AI that is not only capable but conscientious. Key efforts include:
-
Fairness Auditing and Algorithmic Impact Assessments: Evaluating AI models for discriminatory patterns and unintended consequences before deployment.
-
Explainable AI (XAI): Designing systems that offer clear reasoning behind their decisions, especially in high-stakes fields like medicine, law, and finance.
-
Diverse Training Datasets: Ensuring models are trained on data that reflects varied populations, perspectives, and contexts.
-
Regulatory Frameworks: Governments are proposing and enacting legislation to guide ethical AI use:
-
The EU AI Act classifies AI systems by risk level and mandates transparency and accountability measures.
-
The U.S. AI Bill of Rights outlines rights and protections for individuals affected by AI.
-
International initiatives, such as the OECD AI Principles, promote human-centred, transparent, and robust AI design.
-
-
AI Ethics Committees and Standards Bodies: Organisations like ISO, IEEE, and the Partnership on AI are creating global standards for safe and ethical development.
Why It Matters
Unethical AI isn’t just a technical issue—it’s a human one. Without thoughtful design and governance, AI risks reinforcing inequalities, spreading falsehoods, and undermining democratic norms. Ethical AI practices help ensure that innovation benefits all—without compromising human rights, dignity, or trust.
A Call for Collective Responsibility
The future of AI doesn’t belong to any one group. Developers, businesses, policymakers, educators, and the public must collaborate to steer the evolution of AI in ways that are transparent, fair, and inclusive. This requires more than compliance—it calls for a culture of responsible innovation.
Conclusion: The Expanding Role of AI in Our World
Artificial Intelligence is not defined by one singular model or approach—it is a vast ecosystem of tools, systems, and architectures that range from compact, task-specific algorithms to massive neural networks capable of generating human-like text and interpreting complex data.
Small AI models excel in edge environments where power, speed, and efficiency are critical, such as in mobile apps, IoT sensors, and real-time monitoring systems. Meanwhile, large models—like GPT or BERT—leverage enormous datasets and advanced architectures to push the limits of what AI can understand, create, and predict.
At the heart of these systems are weighted neurons and layered architectures that learn iteratively from data—refining their predictions with every pass through the network. These foundational techniques underpin virtually all modern AI systems, from image recognition and language translation to predictive analytics and content generation.
As hardware continues to evolve—with specialised AI accelerators like GPUs and TPUs—and as more data becomes available, AI systems are becoming increasingly accurate, reliable, and widespread in their deployment. Techniques such as distributed training, model quantisation, and on-device inference are also making AI more scalable and accessible.
Looking ahead, the role of AI will only grow. We're already seeing the rise of multimodal models that can interpret text, images, audio, and video together. Edge AI is enabling smarter, privacy-preserving experiences in real-time. And as AI's influence expands, so too does the importance of ethical AI development, with a growing emphasis on transparency, fairness, and accountability.
From industry to everyday life, the development of artificial intelligence is reshaping the way we interact with technology—and it's only just getting started.
Multimodal AI: The Next Frontier
Multimodal AI is emerging as one of the most transformative developments, enabling systems to interpret and respond to multiple types of input at once. Unlike traditional models that specialise in one modality, these systems can interpret the context more holistically, opening new possibilities in applications such as virtual assistants, robotics, education, and accessibility.
Models like OpenAI's GPT-4 with vision or Google's Gemini aim to combine the strengths of language models with visual and auditory understanding. These advances are setting the stage for AI that can see, hear, read, and respond in increasingly human-like ways.
Glossary of Key AI Terms
Understanding the language of artificial intelligence can help demystify how these systems work. Here are some foundational terms used throughout this article:
- LLM (Large Language Model)
- A type of AI model trained on vast amounts of text data to understand, generate, and manipulate human language. Examples include GPT and BERT. LLMs are capable of tasks like translation, summarisation, and content generation.
- Parameters
- The internal values within an AI model that are learned during training. These parameters determine how the model processes input data and generates outputs. Large models may contain billions of parameters.
- Transformer
- A neural network architecture introduced in 2017 that uses self-attention mechanisms to process input data. Transformers are particularly effective for language-related tasks and form the foundation of most modern LLMs.
- Inference
- The stage in the AI pipeline where a trained model is used to make predictions or decisions based on new, unseen data. Inference can take place on cloud servers, local machines, or edge devices.
- Backpropagation
- A core training algorithm used in neural networks to adjust model weights based on prediction errors. It works by propagating the error backward from the output layer to earlier layers, allowing the network to improve its accuracy over time.
- Edge AI
- A deployment strategy where AI models run directly on devices such as sensors, mobile phones, or embedded systems—rather than relying on centralised servers. Edge AI improves response times, reduces latency, and enhances data privacy.
Frequently Asked Questions: How AI Works
- How does an AI model learn from data?
AI models learn through a process called training, where data is passed through a neural network to identify patterns. The model makes predictions, compares them to actual results, and adjusts internal weights using an algorithm called backpropagation. This iterative cycle continues until the model achieves an acceptable level of accuracy.
- What's the difference between small and large AI models?
Small AI models are lightweight, efficient, and often used for specific tasks on devices like sensors or smartphones. Large models, such as GPT and BERT, are trained on huge datasets with billions of parameters and are capable of complex tasks like language generation, summarisation, or image recognition.
- What is a neural network, and why are weights important?
A neural network is a system of interconnected nodes (neurons) that process information. Weights determine how strongly one neuron's output affects another. During training, these weights are adjusted to help the network make more accurate predictions based on input data.
- What is the AI development pipeline?
The AI pipeline includes several key steps: collecting and preprocessing data, selecting a model architecture, training the model, validating/testing its performance, and finally deploying it for inference in real-world applications.
- Can AI work without internet or cloud access?
Yes. Many AI models—especially smaller ones—can run directly on edge devices like smartphones, IoT sensors, or embedded systems. This is called Edge AI, and it reduces latency, improves privacy, and enables offline operation.
- How are transformers different from older AI models?
Transformers are a type of neural network architecture designed for handling sequential data like language. They use mechanisms like self-attention to better understand context across long inputs and are the foundation for modern language models like GPT and BERT.
