Getty AI's Game-Changer: Copyright-Free Image Gen
27-09-2023 | By Robin Mitchell
In an era where artificial intelligence (AI) is revolutionising industries, copyright concerns have emerged as a significant roadblock. How are industry giants navigating these challenges?
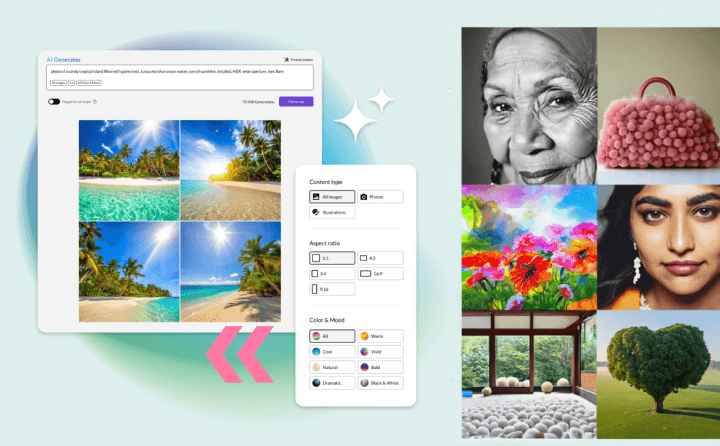
As AI technologies continue to dominate the news, Getty Images has recently announced that its upcoming AI image generator is trained entirely on its proprietary images, providing users with a sigh of relief in regard to copyright laws. What challenges have AI models faced, why is Getty’s upcoming AI significant, and could this be the start of a new gold rush?
Partnering with the industry leader, NVIDIA, Getty Images' AI Generator is not just about merging vast content with cutting-edge AI technology but also reshaping the landscape of creativity and setting new standards in the world of digital imagery.
"We've taken note of our customers' reactions to the rapid rise of generative AI, which encompasses both eagerness and reservations. We've made conscious decisions in the creation of our own tool," shared Getty Images Chief Product Officer Grant Farhall in a statement.
What challenges have AI models faced?
The speed at which AI is finding its way into modern life is truly incredible, with even the simplest devices now incorporating some form of machine learning. But for all the benefits that AI and automation present, there are many who see the inclusion of such technologies as being destructive, both economically and socially.
According to recent studies, the global AI market is expected to reach $126 billion by 2025, emphasising the urgency to address these copyright challenges.
However, fears about the capabilities of AI have yet to do any real damage to its development. New AI start-ups continue to be formed, new applications for AI are constantly discovered, and massive amounts of investment into AI research are being made every single day by businesses and governments alike.
But one area that could potentially throw a spanner in the works on AI development is copyright. Simply put, in order for generative AI systems (such as ChatGPT) to be effective, they require massive amounts of training data. To get this training data, many researchers have scrapped the entirety of the internet for every piece of content they can possibly find, including news sites, research papers, blogs, and forums.
While this content may be freely accessible via web browsers, using that data for purposes other than general browsing is considered by some to be a breach of copyright, especially if that data is used to train AI. This is even more true for image generators that sample work published online, as many of these images cannot be redistributed without a license, nor can they be stored without consent.
Currently, only a handful of lawsuits have been filed, including one joint-action lawsuit that has been filed against OpenAI by numerous authors, including George RR Martin and Jodi Picoult, on the grounds that ChatGPT has been trained on their works without prior permission. Even though these lawsuits are still yet to face a trial, the very threat of lawsuits has already set fear into AI developers.
Getty Images New AI Free From Copyright
Recognising the potential legal implications of AI and training data, Getty Images has recently announced that its up-and-coming generative AI solution is trained entirely on Getty Images-owned data. As Getty Images owns the copyright for all the content that it hosts, the new generative AI will not be violating any copyright laws, and this means that those using the generative AI will also be safe from legal implications.
The AI Image Generation Service by Getty Images offers an end-to-end solution, from ideation to execution, harmonising with the pre-existing Getty Images content libraries. This synergy enhances the entire creative process, ensuring stability and scalability, especially with the backing of NVIDIA's proven computing infrastructure.
One of the standout features of Getty Images' approach to Generative AI is its commitment to compensating content creators, with the company stating that images generated by their tool will pay users whose content has been used for the training.
While the tool has yet to be released, beta testers have noted that generated images are on par with traditional stock footage. However, the tool does have limitations that prevent users from generating any image they want (for example, naming famous individuals is not allowed). Finally, generated images are watermarked by Getty so that they can identify images that have been generated using their tool, as well as giving users the option to detect if an image is AI-generated.

For those interested in experiencing the capabilities of Getty Images' new AI tool firsthand, you can request a demo here.
On a related note, the tech world is buzzing with events that delve deep into the impact of AI on various sectors. For instance, the Code Virtual Experience, priced at just $75, offers exclusive insights into how AI is revolutionising entertainment, media, automotive technology, and gaming. Participants can enjoy live sessions, interviews, and even access recorded content for a month post the event. Such platforms highlight the growing significance and integration of AI in our daily lives, further emphasising the importance of Getty Images' new venture in the realm of AI-generated imagery.
For those interested in diving deeper into these discussions, you can choose to attend the Code event in person or opt for a virtual ticket to gain access to a plethora of insights and sessions.
Could this be a new gold rush?
To see that Getty Images has taken a step in the right direction when it comes to sourcing data for AI training models is great, but what really speaks volumes in this news update is that Getty Images will pay users for submitting content to their library for training on. Simply put, if the numerous lawsuits filed against AI companies such as OpenAI hold up in a court of law, then the AI industry will undoubtedly spark a new gold rush.
As data is invaluable to AI training models, and AI companies need to get permission from data holders, it is very likely that these businesses will start paying individuals to have access to their data to train AI models. This could include anything from website content, blogs, and even personal devices such as smartphones and smartwatches.
It may even become possible for engineers developing products to incorporate data-sharing features that allow users to connect them to AI developers of their choice. Taking this further, data brokers may form that package user data and trade them with AI companies to find the best value for money (essentially making raw data a commodity).
Conclusion
The intersection of AI and copyright laws is a testament to the ever-evolving nature of technology and its implications. As AI continues to shape our world, the onus is on industry leaders, legal experts, and technologists to ensure its ethical and legal deployment. The future of AI is not just about innovation but also about responsible integration
So, will data become the new gold? Possibly. Will AI need to change where and how it gets its data? Most likely!
